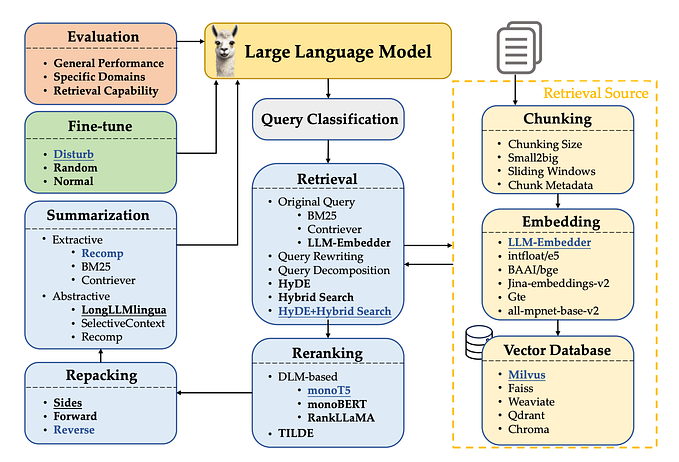
From Words to Vectors: How Embeddings and Vector Databases are Shaping AI

In the world of data science, Machine Learning & AI, Two terms that often pop up are ‘embeddings’ and ‘vector databases’. But what exactly are these? For beginners or those who are not in this field, these terms might sound a bit complex. For those of you who are unfamiliar with these terms. Fear not, as I intent on writing this article as simple terms as possible.
Embeddings in a Nutshell:
Before we get into vectors & vector databases, we first have to understand Embeddings. So? What are these?
Imagine you have a lot of textual data — like.. words in a language. These words have relationships with each other; some are similar, some are opposites. How do we represent this relationship in a way that a computer can understand? This is where embeddings come in play.
Embeddings are a way to convert items (like words, sentences, or even entire documents) into a form (usually a vector or an array of numbers) that captures their meaning or relationship with other items. For instance, in word embeddings, similar words are represented by vectors that are close to each other in a multi-dimensional space. This is incredibly useful in Machine Learning, as it allows most algorithms to work with text data much efficiently.

To make the concept of embeddings simpler, imagine vectors as arrows in space. Each arrow points in a certain direction and has a certain length. In the case of word embeddings, each word in a language is an arrow pointing in a unique direction. Words with similar meanings point in roughly the same direction. For instance, ‘happy’ and ‘joyful’ would have arrows pointing close to each other.
Let’s consider a practical example. Suppose we have 3 words: ‘King’, ‘Queen’, and ‘Man’. In an embedding space, ‘King’ and ‘Queen’ would be closer to each other than ‘King’ and ‘Man’, because ‘King’ and ‘Queen’ are more similar in context. You may use the image above for reference to this.
Vector Databases:
Now, let’s move onto vector databases. Once we have converted our items (like words) into vectors through embeddings, we need a place to store and manage them. Right? This is where vector databases come into play.
A vector database is a specialized database designed to handle vector embeddings. It allows you to store, search and manage large sets of vectors efficiently. For example, if you have a database of word embeddings, a vector database can help you find the most similar words to a given word, based on their vector representations.
Let’s make this a little bit more simpler. Let’s use an analogy. Imagine a vast library with millions of books (vectors). A regular database would be like having these books in piles — It’s there but.. finding a specific book from this pile would be a nightmare. A vector database, on the other hand, is like having a smart library system where each book is precisely placed according to its content, making finding and referencing books (vectors) incredibly more efficient.
For a more concrete example, think of a music recommendation system. Each song in the system can be converted into a vector based on its characteristics like genre, tempo, and mood. These vectors are then stored in a vector database. When you listen to a song you like, the system quickly searches the entire database to find and recommend songs with similar vectors — meaning similar characteristics.
So how do they work together? — A Real-world Scenario:
Embeddings and vector databases often work together hand in hand. First, embeddings convert data (like words) into a format that captures the essence or relationship of the data. Then, vector databases manage these embeddings, allowing for efficient storage, retrieval, and analysis. This combination is powerful in various applications like recommendation systems, natural language processing, and image recognition.
Imagine you are building a chatbot. You want this chatbot to understand and respond to user queries appropriately. You start by creating word embeddings for the common phrases and questions users might ask. These embeddings are then stored in a vector database. So when a user types a query, the chatbot converts it into a vector, searches the database for the closest matching vectors, and then formulates a response based on the most similar phrases it has learned.
Latest & Some Foundational Embedding Techniques:
For those of you who are looking to learn advanced embedding techniques, Here are some that you might find interesting:
- Word2Vec and GloVe: Foundational techniques for representing words as vectors, still widely used in text analysis and NLP.
- Multimodal Embeddings: It combines embeddings from different modalities like text and images to create richer representations. Techniques like CLIP (Contrastive Language-Image Pre-training) and BEVD (Bimodal Encoder Decoder) are gaining traction.
- Contextual Embeddings: Capturing the meaning of words depending on their context using techniques like Transformers and BERT. Exploring time-aware and dynamic contextualization for evolving data.
- Knowledge-Enhanced Embeddings: Incorporating external knowledge sources like ontologies and knowledge graphs into the embedding process for improved accuracy and interpretability. Techniques like KG-BERT and KGE (Knowledge Graph Embeddings) are noteworthy.
- Hyperbolic Embeddings: Using hyperbolic geometry for capturing relationships between entities, especially useful for representing hierarchical or tree-like structures. Research on efficient indexing and retrieval for hyperbolic spaces is currently ongoing.
- Federated Learning and Distributed Embeddings: Learning embeddings from decentralized data while preserving privacy, crucial for handling sensitive data and collaborative learning. Federated Averaging and Differentially Private SGD are some of its examples.
Popular Vector Databases:
Some of the most popular and widely used Vector Databases are:
- Milvus: Open-source vector database known for scalability and efficiency, used by companies like Alibaba and Tencent.
- Pinecone: Cloud-based vector database with a focus on ease of use and integration with machine learning pipelines.
- Weaviate: Open-source vector database designed for storing and searching linked data, with semantic search capabilities.
- Chroma: Open-source database optimized for integration with Large Language Models, enabling retrieval-augmented generation.
- Qdrant: Vector database with a focus on flexibility and advanced filtering options for complex search scenarios.
- Faiss: Library from Facebook AI Research for efficient similarity search and clustering of dense vectors, often used as a building block for vector databases.
- Annoy: Library for approximate nearest neighbor search, offering a balance of speed and accuracy.
If you plan on using a vector database, be sure to consider things like your use case, the kind of data you’ll be working with, performance requirements, and data privacy.
Conclusion:
In conclusion, embeddings and vector databases are like peanut butter and jelly — they just work perfectly together. Embeddings help in translating complex, unstructured data into a structured numerical format, while vector databases handle these numerical formats with ease, allowing for a quick search, retrieval and analysis. This synergy is what powers many of the sophisticated machine learning & AI applications we see today, from search engines to personalized shopping recommendations to Large Language models (Like GPT & Bard).
Before you go
I hope these examples and analogies have helped you understand the concepts of embeddings and vector databases. If you’re just starting in data science or are curious about these terms, I hope this article has been helpful. Stay tuned for more that break down complex tech topics into simple explanations! Please consider following me on | GitHub | LinkedIn | Kaggle | Website
Vishnu Viswanath